TurboQuant, Google Research tarafından geliştirilen ve büyük dil modellerinin Key-Value (KV) önbelleğini teorik sınıra yakın şekilde sıkıştıran bir kuantizasyon algoritmasıdır. Hiç eğitim gerektirmeden 3 bit'e iner, doğruluk kaybı yoktur ve H100 GPU'larda 8 kat hız artışı sağlar.

TurboQuant Nedir?
TurboQuant, Google Research'ün 2025-2026 yıllarında geliştirdiği üç yeni sıkıştırma algoritmasından biridir: TurboQuant, QJL ve PolarQuant. Bu algoritmaların ortak amacı, büyük dil modellerinin (LLM) çalıştırılması sırasında oluşan yüksek boyutlu vektörleri minimum bilgi kaybıyla maksimum düzeyde sıkıştırmaktır.
Klasik kuantizasyon yöntemleri vektörleri küçültürken her veri bloğu için ayrıca normalleştirme sabitleri saklamak zorundadır. Bu sabitler veri başına 1-2 ekstra bit demektir. Milyarlarca vektörde bu gizli ek yük ciddi boyutlara ulaşır. TurboQuant bu sorunu kökten çözer: normalleştirme sabitine hiç ihtiyaç duymaz.
LLM'lerde KV Önbelleği Nedir, Neden Sorun Çıkarır?
Transformer mimarisine dayanan dil modellerinde her dikkat (attention) katmanı, işlediği tüm önceki token'ların Key (K) ve Value (V) vektörlerini bellekte tutar. Bu yapıya KV önbelleği (KV cache) denir.
Bağlam uzunluğu arttıkça KV önbelleği katlanarak büyür. 128K token bağlamında çalışan bir modelde KV önbelleği, modelin kendi ağırlık matrislerinden daha fazla GPU belleği tüketebilir. 1M token bağlam hedeflenen günümüz modellerinde bu sorun daha da kritik hale gelir.
Standart yaklaşım bu vektörleri 8-bit veya 4-bit'e kuantize etmektir. Ancak her blok için ölçekleme sabiti (scale factor) saklamak zorunda olunduğundan teorik sıkıştırma oranına hiçbir zaman tam ulaşılamaz.
TurboQuant Nasıl Çalışır?
TurboQuant iki adımdan oluşur:
Adım 1 — PolarQuant ile yüksek kaliteli sıkıştırma: Vektörler önce rastgele bir rotasyon matrisiyle döndürülür. Bu dönüşüm verinin geometrisini düzleştirir ve klasik kuantizasyonu neredeyse mükemmel hale getirir. Ardından Kartezyen koordinatlar yerine polar koordinatlar kullanılır. "Güç" bilgisi yarıçapta, "anlam" bilgisi açıda taşınır. Attention mekanizması açısal benzerliğe dayandığından yarıçap zaten iptal olur; açılar birim hiperküre üzerinde doğal olarak sınırlı olduğundan normalleştirme sabitine gerek kalmaz.
Adım 2 — QJL ile hata düzeltme: PolarQuant'ın bıraktığı küçük artık hatalar, QJL (Quantized Johnson-Lindenstrauss) algoritmasıyla yalnızca 1 bit kullanılarak düzeltilir. Her vektör elemanı +1 veya -1'e indirgenir. Johnson-Lindenstrauss teoremi, bu işlemin yüksek boyutlu uzaydaki mesafeleri koruduğunu matematiksel olarak garanti eder.
Sonuç: ek bellek yükü sıfır, sıkıştırma oranı teorik sınıra yakın.
PolarQuant Nedir?
PolarQuant, TurboQuant'ın ilk aşamasını oluşturan bağımsız bir sıkıştırma algoritmasıdır.
Kartezyen koordinatlarda (x, y, z) şeklindeki bir vektörü kuantize etmek için her eksenin kendi normalleştirme katsayısı gerekir ve bu katsayılar bellekte yer kaplar.
PolarQuant bunun yerine vektörü polar/hiperküre koordinatlara çevirir:
- Yarıçap (r): vektörün büyüklüğünü taşır
- Açılar (θ₁, θ₂, ...): yönü — yani anlamı taşır
Dikkat hesaplamalarında önemli olan nokta çarpımı (dot product), yalnızca yön bilgisine duyarlıdır; büyüklük iptal olur. Açılar birim hiperküre üzerinde zaten normalize olduğundan dışsal bir sabit tutmaya gerek yoktur.
QJL Nedir? Johnson-Lindenstrauss Dönüşümü Ne İşe Yarar?
QJL (Quantized Johnson-Lindenstrauss), her vektör elemanını tek bir işaret bitine (+1 veya -1) indirgeyen bir sıkıştırma yöntemidir.
İlk bakışta agresif bir bilgi kaybı gibi görünür. Ama Johnson-Lindenstrauss lemması şunu söyler: yeterli sayıda boyuta sahip bir uzayda, rastgele projeksiyon işaret bitleri kullanılarak iki vektör arasındaki açı yüksek doğrulukla tahmin edilebilir.
Klasik kuantizasyonda her blok için scale ve zero_point değerleri saklanır. QJL'de bu tamamen ortadan kalkar; algoritma veriyi doğrudan normalize bir uzaya projeliyor.
Pratik sonuç: 3 bitlik efektif depolama gerçekten 3 bit demek, gizli ek maliyet yok.
TurboQuant Benchmark Sonuçları: Doğruluk Kaybı Var Mı?
Testler Gemma ve Mistral modellerinde beş kıyaslama setiyle yapıldı: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER ve L-Eval.
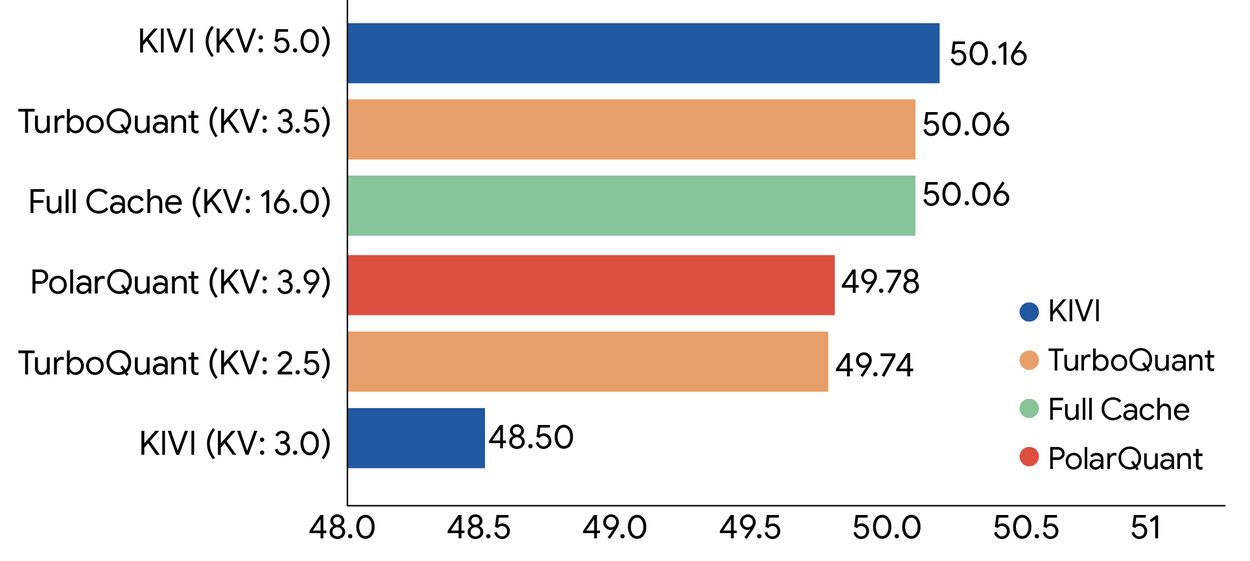
3 bit KV önbelleğiyle çalışırken TurboQuant, tam hassasiyetli baz modelle neredeyse aynı puanları aldı. Tüm kıyaslama setlerinde fark ihmal edilebilir düzeyde.
Dikkat puanlarındaki sapma grafiğinde TurboQuant, rakip yöntemlere göre belirgin şekilde daha az hata üretiyor. Özellikle 1-bit QJL'nin bias düzeltme etkisi burada açıkça görülüyor.
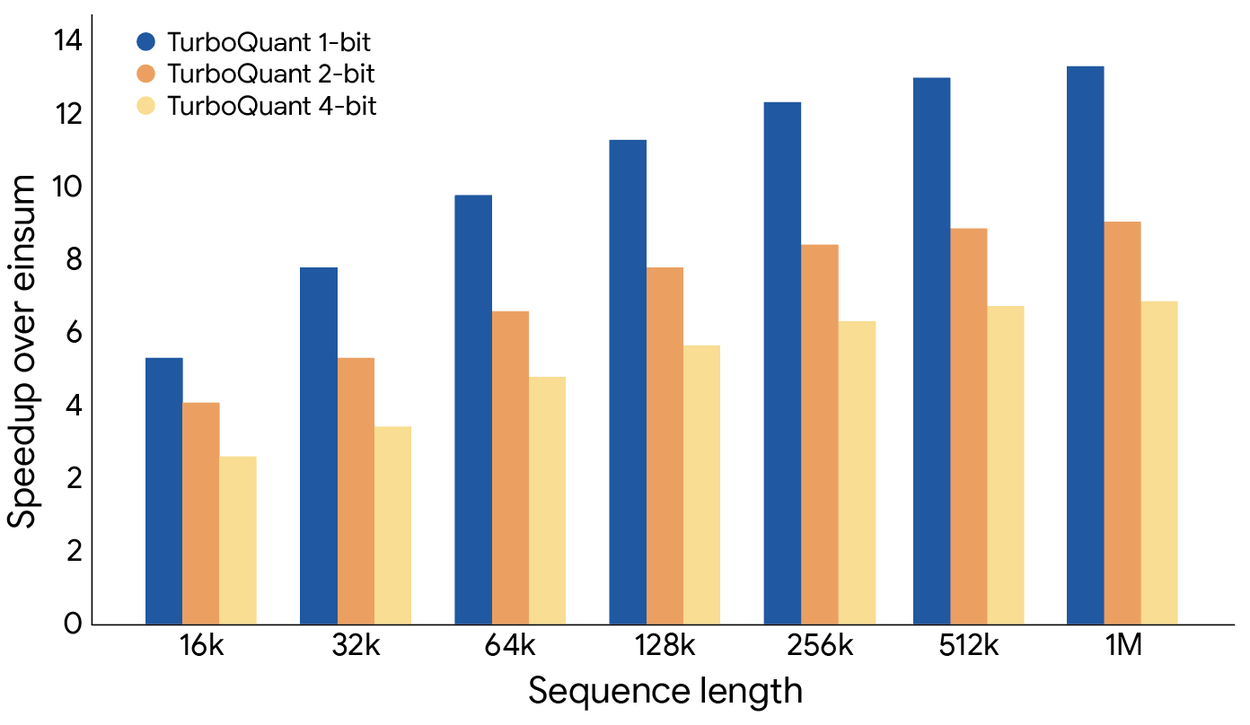
H100 GPU'larda yapılan hız testinde:
- 8× throughput artışı (32-bit quantize edilmemiş anahtarlara kıyasla)
- 6× daha az KV bellek kullanımı
- Eğitim veya fine-tuning gereksinimi: sıfır
TurboQuant Vektör Arama Motorlarında da Çalışıyor Mu?
Evet. TurboQuant yalnızca LLM çıkarımıyla sınırlı değil. Milyarlarca yüksek boyutlu vektörün depolanıp sorgulandığı vektör arama motorları için de test edildi.
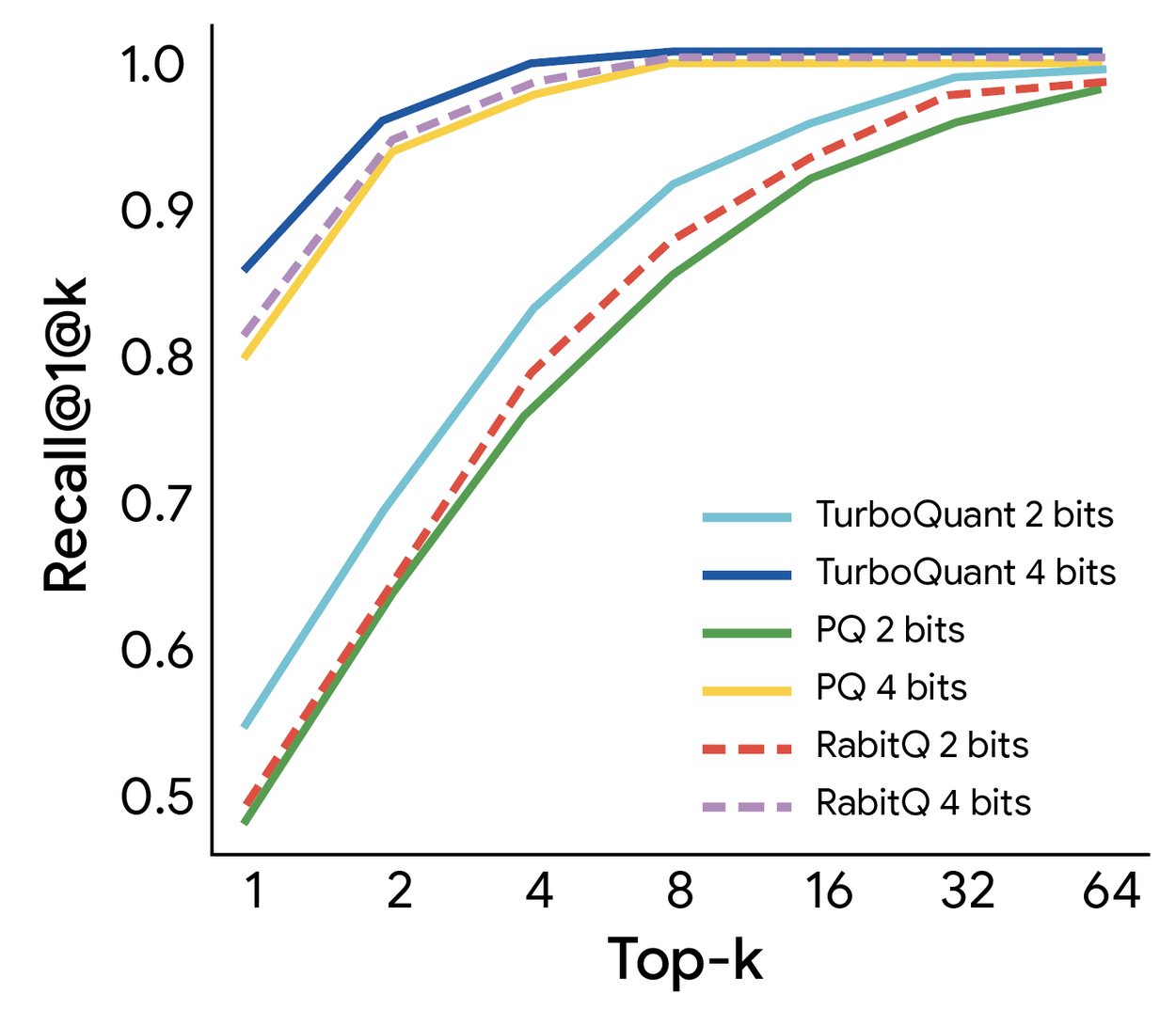
Product Quantization (PQ) ve RabbiQ gibi mevcut yöntemlerle karşılaştırıldığında PolarQuant ve TurboQuant:
- Daha yüksek recall (geri çağırma) oranı elde etti
- İndeks oluşturma süresini de önemli ölçüde kısalttı
Bu iki sonucu aynı anda elde etmek nadir görülür; çoğu sıkıştırma yöntemi birini diğerine feda eder. Semantik arama sistemlerinde bu demek ki: hem daha küçük indeks, hem daha hızlı sorgu, hem de daha iyi sonuç.
TurboQuant Neden Önemli? Hangi Problemi Çözüyor?
Büyük modeller için çıkarım maliyeti gerçek bir kısıtlamadır. Bağlam uzunluğu arttıkça KV önbelleği belleğin giderek büyük bir bölümünü tüketir. TurboQuant bu denklemi değiştirir:
- Aynı donanımda daha uzun bağlam: 6× bellek tasarrufu doğrudan daha uzun context window anlamına gelir
- Daha büyük batch size: bellek açıldığında aynı GPU'da daha fazla istek paralel işlenir
- Daha hızlı çıkarım ve düşük maliyet: 8× throughput artışı, daha düşük servis maliyeti anlamına gelir
- Eğitim gerektirmez: mevcut modellere direkt uygulanabilir
Kimler Geliştirdi? Makaleler Nerede?
Yazarlar: Amir Zandieh (Research Scientist) ve Vahab Mirrokni (VP & Google Fellow), Google Research
Üç makale ICLR 2026 ve AISTATS 2026'da sunulacak.
Kaynak: Google Research Blog
Makaleler: TurboQuant · QJL · PolarQuant
