TurboQuant is a quantization algorithm developed by Google Research that compresses large language model Key-Value (KV) caches to near-theoretical limits. It reaches 3-bit effective storage with no accuracy loss, delivers 8× throughput on H100 GPUs, and requires no training or fine-tuning.

What Is TurboQuant?
TurboQuant is one of three compression algorithms published by Google Research: TurboQuant, QJL, and PolarQuant. Their shared goal is to compress the high-dimensional vectors produced during LLM inference to the absolute minimum — while preserving full accuracy.
Classical quantization methods compress vectors but must store normalization constants alongside each data block. That's 1–2 extra bits per number. Across billions of vectors, this hidden overhead is substantial. TurboQuant eliminates it entirely: it stores no normalization constants whatsoever.
What Is the KV Cache in LLMs — and Why Is It a Problem?
In Transformer-based models, every attention layer stores the Key (K) and Value (V) vectors for all previously seen tokens. This structure is called the KV cache.
As context length grows, the KV cache grows with it. At 128K tokens, the KV cache can occupy more GPU memory than the model's weight matrices. With 1M-token context windows becoming common, this problem is increasingly critical.
Standard practice is to quantize these vectors to 8-bit or 4-bit. But storing scale factors per block means the theoretical compression ratio is never actually achieved.
How Does TurboQuant Work?
TurboQuant operates in two steps:
Step 1 — High-quality compression with PolarQuant: Vectors are first passed through a random rotation matrix. This flattens the data geometry and makes standard quantization nearly perfect. Vectors are then converted from Cartesian to polar/hyperspherical coordinates. Magnitude lives in the radius; meaning lives in the angles. Because dot-product attention depends only on angular similarity, the radius cancels out mathematically. Angles on a unit hypersphere are naturally bounded — no external normalization constant needed.
Step 2 — Error correction with QJL at 1 bit: The small residual error left by PolarQuant is corrected by QJL (Quantized Johnson-Lindenstrauss) using a single bit per value. Every vector element is reduced to its sign (+1 or −1). The Johnson-Lindenstrauss transform mathematically guarantees that distance relationships between vectors are preserved.
Result: zero memory overhead, compression at the theoretical limit.
What Is PolarQuant?
PolarQuant is the first stage of TurboQuant and a standalone compression algorithm.
Quantizing a Cartesian vector (x, y, z) requires normalizing each axis separately — those normalization coefficients must be stored somewhere in memory.
PolarQuant instead converts vectors to polar/hyperspherical coordinates:
- Radius (r): encodes magnitude
- Angles (θ₁, θ₂, ...): encode direction — i.e., meaning
In attention, only directional similarity matters. The dot product between two unit vectors is a function of their angle alone; magnitude cancels out. Since angles are naturally bounded on a unit hypersphere, no external normalization constant is needed.
QJL (Quantized Johnson-Lindenstrauss) reduces every vector element to a single sign bit: +1 or −1.
This looks like aggressive information loss. But the Johnson-Lindenstrauss lemma guarantees that in a high-dimensional space, a random projection using only sign bits can estimate the angle between two vectors to high accuracy.
Classical quantization stores a scale and zero_point per data block. QJL stores nothing — the algorithm projects data into a space where normalization is implicit.
In practice: 3-bit effective storage actually costs 3 bits. No hidden tax.
TurboQuant Benchmark Results: Is There Any Accuracy Loss?
Tests ran on Gemma and Mistral across five benchmarks: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval.
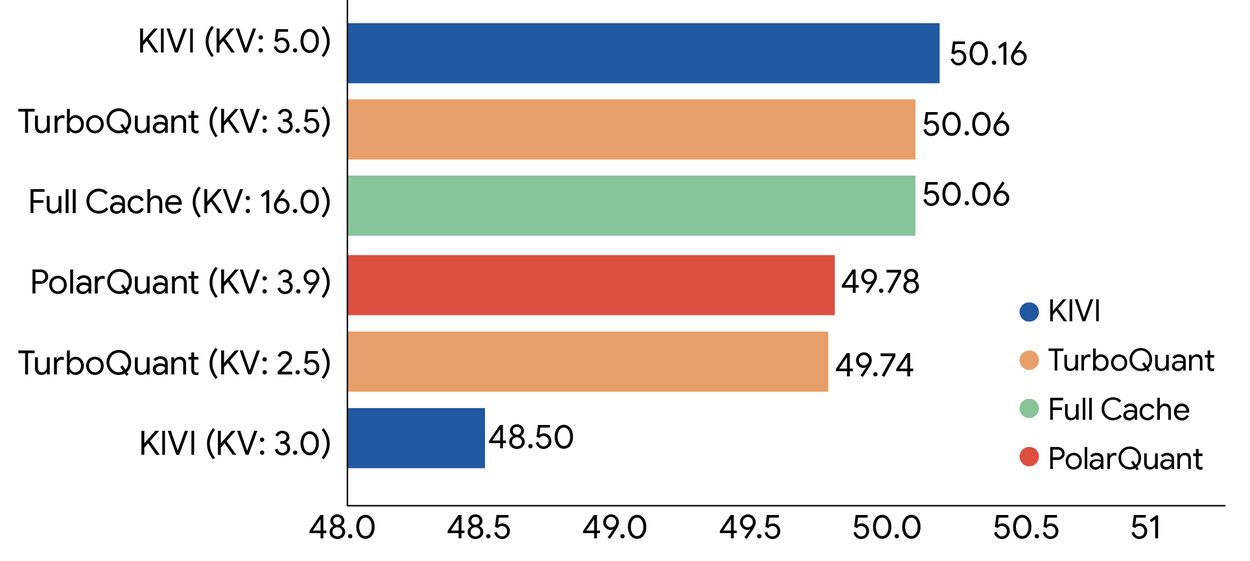
At 3-bit KV compression, TurboQuant matched baseline accuracy across all benchmarks. The gap is negligible — not a tradeoff, a genuine free lunch.
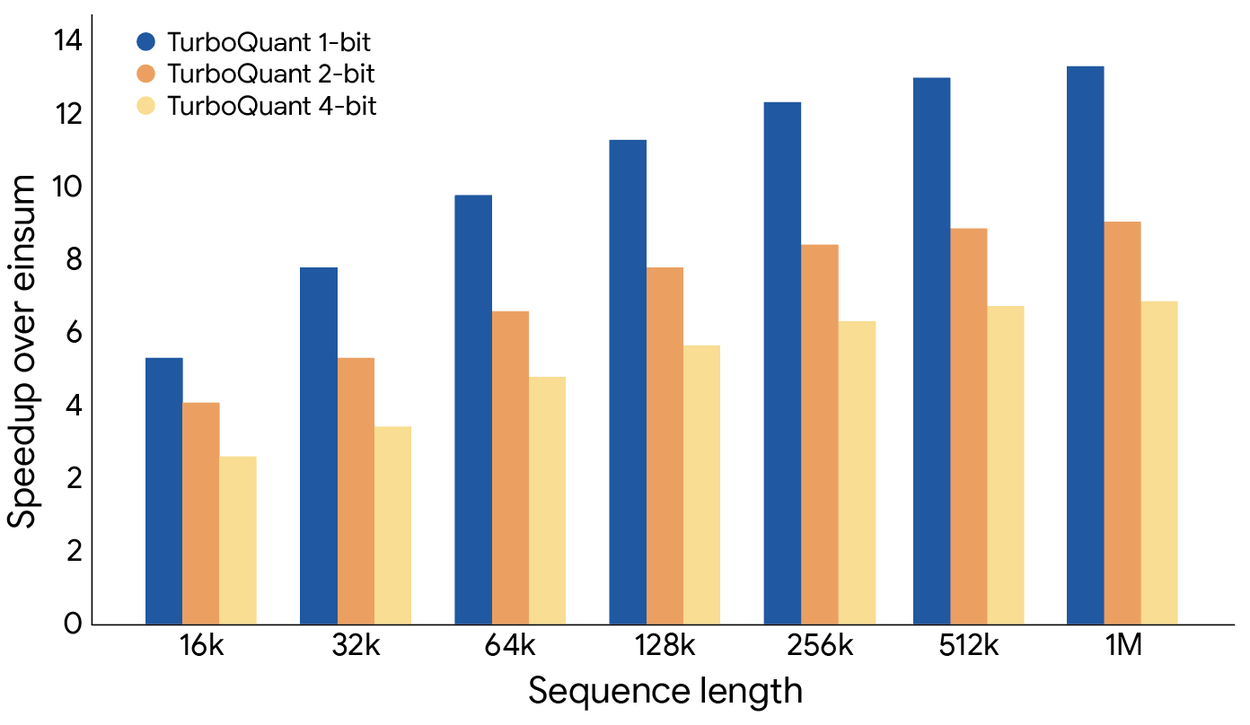
In attention logit distortion (how much compressed vectors deviate from originals), TurboQuant significantly outperforms competing methods. The QJL bias-correction step is clearly visible — it cuts the distortion that PolarQuant alone would leave behind.
Results on H100 GPUs:
- 8× throughput compared to 32-bit unquantized keys
- 6× reduction in KV memory footprint
- Training or fine-tuning required: none
Does TurboQuant Work for Vector Search?
Yes. TurboQuant isn't limited to LLM inference. The same algorithms were tested on vector search — storing and querying billions of high-dimensional embeddings.
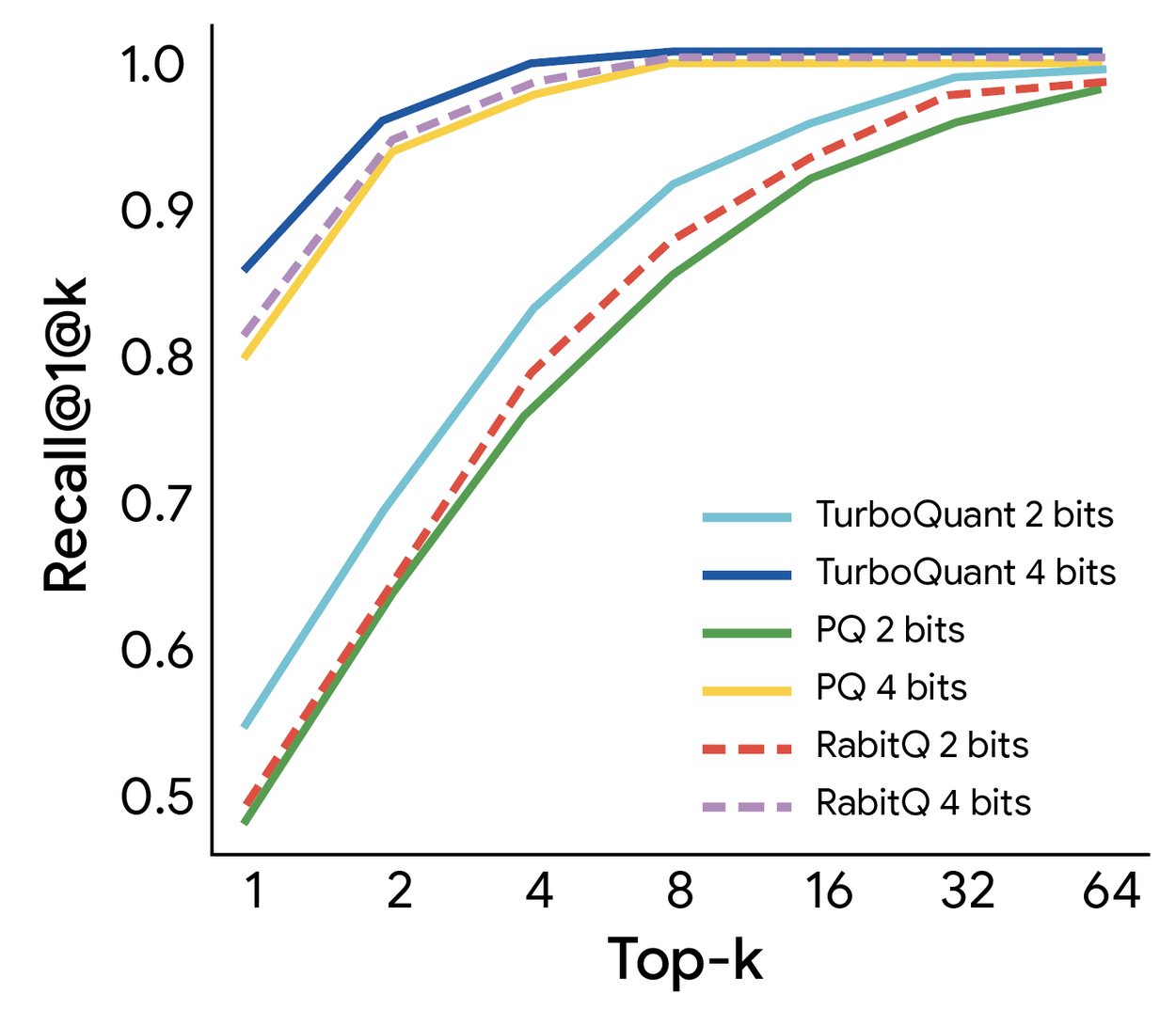
Compared to Product Quantization (PQ) and RabbiQ, PolarQuant and TurboQuant achieved:
- Higher recall ratios
- Faster index-building time
Getting both simultaneously is unusual. Most compression methods trade one for the other. For semantic search at scale, this means smaller indices, faster queries, and better results — all at once.
Why Does TurboQuant Matter? What Problem Does It Actually Solve?
Inference cost is a real constraint for large models. As context windows push toward 1M tokens, the KV cache can dominate GPU memory. TurboQuant changes the equation:
- Longer context on the same hardware: 6× memory reduction directly translates to longer context windows
- Larger batch sizes: freed memory means more parallel requests per GPU
- Faster inference, lower serving cost: 8× throughput means dramatically lower cost per token
- No training required: drop-in applicable to existing models
Who Built TurboQuant? Where Are the Papers?
Authors: Amir Zandieh (Research Scientist) and Vahab Mirrokni (VP & Google Fellow), Google Research
All three papers are being presented at ICLR 2026 and AISTATS 2026.
Source: Google Research Blog
Papers: TurboQuant · QJL · PolarQuant
